はじめに
2024年のGWももう終わりですね。今年は旅行の予定を入れてませんでしたが、家事をやっていたらあっという間に過ぎました。
今回はSEOについて書きました。ブログ作成や Next.js を勉強している初期段階で SEO 対策として Metadata を付与する説明があり、「SEO って何?」、「どうして必要なの?」という疑問が湧き、調べてみました。 合間合間で書いているので記事を書くのに時間がかかってしまいましたが、その分同じように SEO 対策 Next.js でどうやるのか分からない人の参考になれば嬉しいです。
SEO 対策とは
SEO (Search Engine Optimization: 検索エンジン最適化) 対策とは Google などの検索サイトで、対象の Web サイトが上位表示されるための施策です。 上位に表示させることでユーザがアクセスする機会を増やすことができます。
検索エンジンの仕組み
上位表示させるためには、まず検索エンジンの仕組みを簡単に理解する必要があります。以下の図がわかりやすいです。
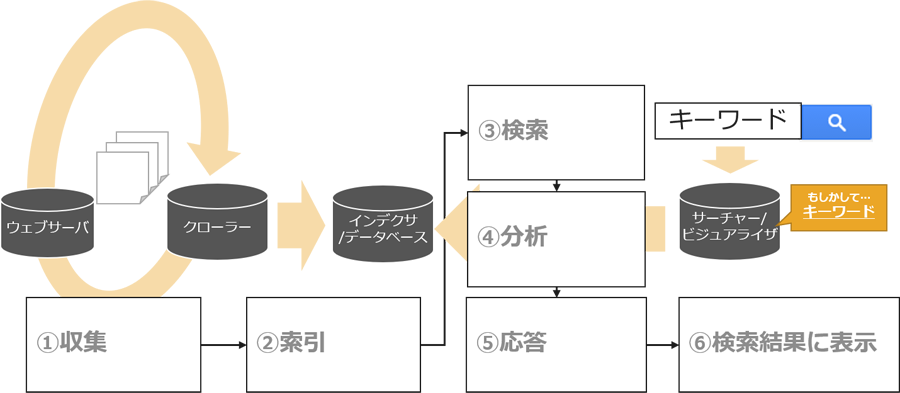
クローラーが日夜 Web サイトを巡回してインデックスを作成しています。 そして、ユーザが検索すると、検索キーワードに対して検索評価アルゴリズムが収集されたインデックスからランキングを作成し、スパムなどを取り除いた上で上位から順に表示しています。ですので、SEO 対策をするには、
- クローラーに登録してもらえるように必要な情報を設定すること
- 検索評価アルゴリズムに評価してもらえるように情報の質を高めること
が必要になります。今回、Next.js で実装するところは主に 1 つ目です。
検索評価アルゴリズムに評価してもらうためには
日本での検索エンジンのシェアは Google が強い。Google では検索エンジン最適化(SEO)スターター ガイドを公表している。このガイドとその補足説明をしているこちらの記事がとてもわかりやすかった。 日本での検索エンジンのシェアは Google が強いです。Google では検索エンジン最適化(SEO)スターター ガイドを公表しています。 このガイドとその補足説明をしているこちらの記事がとてもわかりやすかったです。
- Google がコンテンツを見つけられるようにする
site: <ドメイン>で出てくれば OK- 出てこない場合は、他のクロール済みのサイトにリンクを貼ってもらうこと
- 技術的にはサイトマップを作る
- 検索から除外したいものを適切に指示すること
- サイトを整理する
- URL を見ただけで何が書かれているかわかりやすくする
- 類似トピックのページをディレクトリにまとめる
- 異なる URL で同じページを表示するといった重複コンテンツを避ける
- 興味深く有益なサイトにする
- 共通として下記を意識する
- 文章がよく整理されていて、読みやすい
- コンテンツに独自性がある
- コンテンツが最新
- コンテンツが有用で信頼性が高く、ユーザファーストである
- 読者の検索ワードを予測する
- 不要が広告を避ける
- 関係のあるリソースのリンクを貼る
- 共通として下記を意識する
- Google で検索された時の見え方を意識する
- タイトルを制御する
- スニペットを制御する
- 最適化した画像をサイトに追加する
- 関連するテキストの近くに高画質の画像を追加する
- 画像にわかりやすい代替テキストをつける
- 動画を最適化する
- Web サイトを宣伝する
ざっくり、このくらいのことが書かれています。結局は内容・UI などなど、ユーザにとって良いものにすることが良いということがわかりました。(がんばらないと...)
逆にこれは関係ないということもガイドには書いてあります。特にキーワードは関係ないというのが興味深かったので、興味ある人はガイドを見てみると良いでしょう。
どこまで効力があるかはわからないですが、学んだことを踏まえて以下を実装でやってみようと思います。
- サイトマップを作る
- URL を見ただけで何が書かれているかわかりやすくする
- タイトル・スニペットを制御する
実装
Next.js の Metadata をまとめたいことが本記事の目的なので本記事の目的なので、順番が前後しますがタイトル・スニペットから説明します。
タイトル・スニペットを制御する
まず、タイトル・スニペットを制御するというのは下記のように title タグと description の meta タグを適切なものにつけましょうということです。
スターターガイドでは良いtitleやdescriptionの付け方について説明しているので興味がある人はスターターガイドをご参照ください。
<head>
<meta charset="UTF-8" />
<title>タイトル</title>
<meta name="description" content="ここに説明文を書く" />
</head>これを Next.js で実装する方法は、公式ドキュメントに記載されているMetadataもしくはgenerateMetadataを使用します。従来の Pages Router では Head コンポーネントを使えばよかったのですが、App Router では Metadataを使用します。
静的なメタデータの場合はMetadataを、動的なメタデータの場合はgenerateMetadaを使用します。今回は静的なものを扱うのでMetadataについてまとめます。
generateMetadataについてはこちらの記事が参考になると思います。
Meatadataの使い方についてはMetadata型を export するだけです。
共通で設定したい場合は layout.tsx に、特定のページに設定したい場合は page.tsx に、以下のようなコードを記述すれば設定できます。
import { Metadata } from "next";
export const metadata: Metadata = {
title: "Acme Dashboard",
description: "The official Next.js Course Dashboard, built with App Router.",
};実際に自分でコードを作って学びたい方はLearn Next.js の 16 章をやるのが一番良いと思います。 私もこの Learn Next.js をやる中で SEO ってなんだっけ?となりこの記事を書くに至りました。
Metadataで指定できる値を通していろいろな要素を学べそうだったのですが、長くなりそうだったので別記事で後日公開しようと思っています。
サイトマップを作る
サイトマップについてはGoogle 検索セントラルで説明されています。初めてのブログ構築でまだ外部リンクも少ないので、実装してみます。
サイトマップには、XML サイトマップ、RSS、テキストサイトマップといった種類がありますが、ベーシックな XML サイトマップを今回は扱います(RSS については今後導入していきたいですね)。サイトマップの XML のフォーマットはsitemaps.orgで公開されています。 sitemap.xmlの説明や知りたいことはsitemap.xml(XMLサイトマップ)の作り方に書いてあったので割愛します。
sitemap.xmlを都度自分で描くのは大変なのでこちらの記事を参考にnext-sitemapを使って生成します。 記事内でnext-sitemapとnextjs-sitemap-generatorを比べていましたが、githubのスター数やメンテ情報を見ると、next-sitemapを使っている人の方が多そうです。
導入はとても簡単です。
-
パッケージのインストール
pnpm install -D next-sitemap -
config ファイルの作成
module.exports = { siteUrl: "https://kmnky.dev", generateRobotsTxt: true, // robots.txtを生成するか sitemapSize: 7000, // サイトマップの分割サイズ outDir: "./out", // サイトマップの出力先 }; -
パイプラインで出力する際のコマンドに追加する
// package.json { "scripts": { // next build以下に生成コマンドを追加する "build": "next build && next-sitemap --config sitemap.config.js", }, }
これでビルドコマンドを実行すると、sitemap.xml, sitemap-0.xml, robots.txtが出力されます。
sitemap.xml- 本体。これをGoogle Search Consoleに登録します。一度登録すれば他の検索サイトでもヒットするそうです。
- スクレイピングできるようになるのでルート直下に置かない記事もありましたが、今回は問題となる情報をおかないのでルートのままで公開します。
sitemap-0.xml- サイズを分割するためのものです。設定したサイズを超えると1,2といったように新しいXMLファイルが生成されます。
- クローラは
sitemap.xmlに書いてあるlocを見て本XMLを見つけてきます。
robots.txt- こちらもSEO対策としてよく出てくるファイルです。
- クローラに対して、クロール不要なページを指定することでクロールの最適化をすることができます。
- User-agent : どのクローラに対して適用するかを指定する
- Disallow : クロールしないページを指定する
- Sitemap : sitemap.xmlの場所を記載する
- 下記のようなテキストが生成されました。
# * User-agent: * Allow: / # Host Host: https://kmnky.dev # Sitemaps Sitemap: https://kmnky.dev/sitemap.xml
この生成されたファイルをデプロイしてあげれば完了です。
URL を見ただけで何が書かれているかわかりやすくする
こちらは簡単です。
今まで日付パスにしていましたが、日付+キーワードとなるようにパスを修正します。 現状、アップロードしているMarkdownファイル名をパスにしているのでファイル名を修正するだけです。
おわりに
以上、私のような初心者でも始められるSEO対策について紹介しました。 クローラなど普段意識していないことをたくさん学べて充実した学習でした。
本当はNext.jsで用意されているMetadata APIを通して、opengraphやtwitterなどの内容を記事にしたかったですが、量が多くなりそうなので次回の記事にしようと思います。
記事も多くなってきたのでそろそろタグの導入を検討していきます。 まだまだ見づらいサイトだと思いますが、引き続き見ていただけると嬉しいです。 最後まで読んでいただきありがとうございました。
参考
検索品質評価ガイドライン
Google の SEO 対策を調べるとよく「検索品質評価ガイドライン」や「E-A-T」などの言葉が出てきます。スターター ガイドにも書かれていますが、これ自体は直接評価には関係していないので注意が必要です。
Google は評価アルゴリズムが適切に結果を表示してくれているのかを外部委託して評価していますが、その委託業者が評価するにあたって検索品質評価ガイドラインが使われています。つまり、Google が上位表示してほしいと考えているサイトはこのようなものと解釈できます。そのため、直接評価には関係ないですが、意識しておくと良いサイトができると思います。知っていて損はないでしょう。
こちらの記事などがわかりやすいです。 以下、その要点を記載します。
- Page Quality
- E-E-A-T
- Experience(経験)
- コンテンツ作成者がそのトピックに必要な体験をしているか、その経験量はどれくらいか
- 例: 実際の使用経験をもとにした体験談は一般的なネット情報より価値が上がる
- Expertise(専門性)
- コンテンツ作成者がそのトピックに必要となる知識や技術をどれくらい持っているか
- 例: 医者が書いた医学的記事の方が普通のライターより価値が上がる
- Authoritativeness(権威性)
- コンテンツ作成者がそのトピックに関してどのくらい認知されているか
- 例: プロ選手の記事の方がなも知らない人の記事よりも価値が上がる
- Trustworthiness(信頼性)
- ページの正確性や誠実性、安全性、信頼性の量
- サイト作成者本人が何者であるかを書く方が良い
- Experience(経験)
- メインコンテンツの品質と量
- サイトの評判
- E-E-A-T
- 使いやすさ
- PC だけでなくモバイルでの使いやすさを意識しているか
- データの入力が面倒、画面が小さい、接続が遅い etc.
- Needs Met (需要との一致)
- ユーザのニーズに検索結果がどれだけ満たせているか
参考記事
- 出典:IREP 検索エンジンの仕組み_
- 検索エンジン最適化(SEO)スターター ガイド
- Google の SEO 対策で大切なことは、Google が教えてくれた【2024 年最新版】
- Google に評価される SEO の基準は?具体的な対策手法を 3 つ解説
- 【徹底解説】E-E-A-T とは?SEO における Google の評価基準やその対策を紹介
- Google が示す検索品質評価ガイドラインとは?おさえるべきポイントを解説
- Google 検索品質評価ガイドラインとは?要点や有効な活用方法など徹底解説!
- Next.js Metadata Object and generateMetadata Options
- API で取得したデータをもとに、動的にメタ情報を設定する方法(Next.js App Router)
- Google 検索セントラル サイトマップについて
- sitemap.xml(XMLサイトマップ)の作り方
- Next.js に next-sitemap を導入して超手軽にサイトマップ sitemap.xml を生成しよう